MTP(Multi-Token-Prediction) 的作用
核心思想:通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。
具体来说,在训练阶段,一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个token,实现成倍的推理加速来提升推理性能。
例如, Better & Faster Large Language Models via Multi-token Prediction, 通过设置, 并训练训练共享的多头模型. 如下图所示.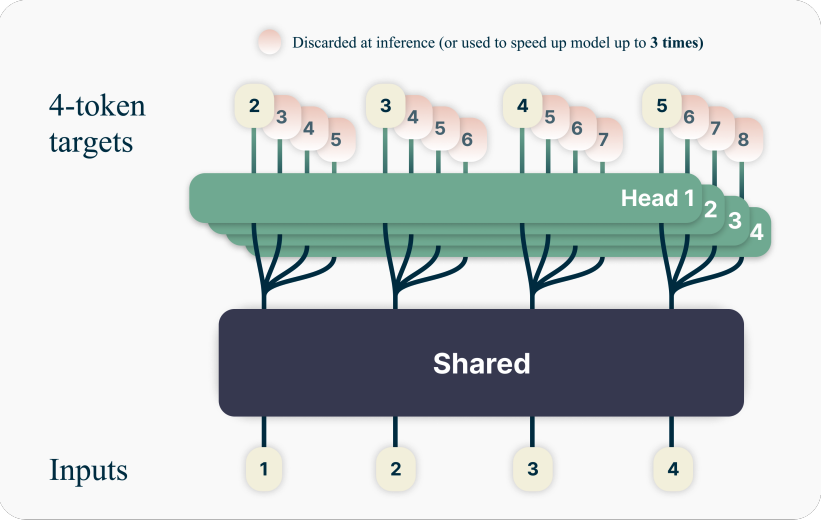
DeepSeek-v3版实现
MTP实现图如图所示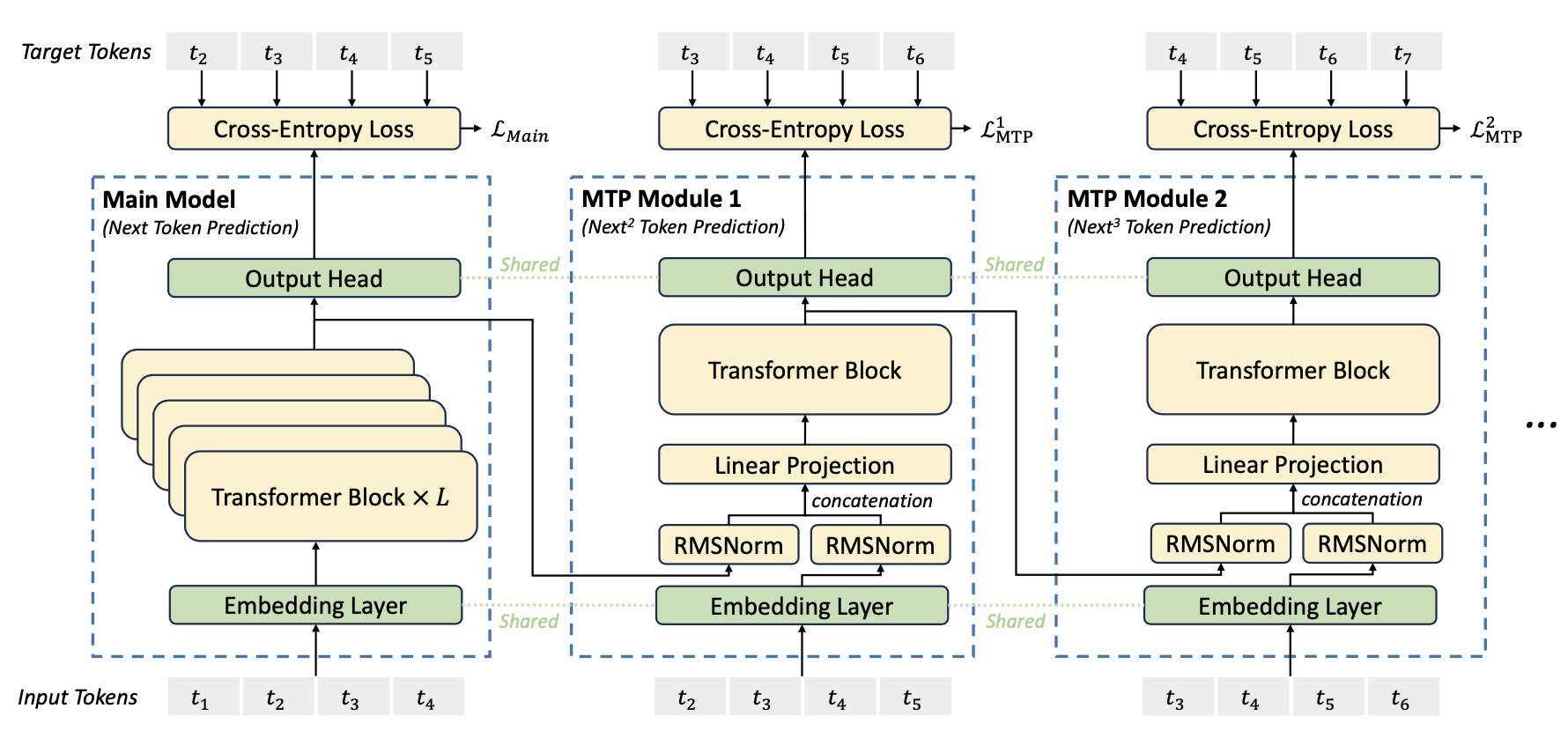
在MTP模块中:
- 主模型的TRM的计算结果$h_{i}^{k-1}$, 在进入Output Head层计算前, 这部分数据传递到MTP层参与后面的计算. 即与下一次token的输入做拼接. $$\mathbf{h}_i^{\prime k}=M_k\left[\operatorname{RMSNorm}\left(\mathbf{h}_i^{k-1}\right) ; \operatorname{RMSNorm}\left(\operatorname{Emb}\left(t_{i+k}\right)\right)\right],$$
- 一个线性投影层, $M_{k} \in \mathbb {R}^{d \times 2d}$组成。
- 一个TRM层$TRM_{k}(·)$
训练
可以看到, MTP模块是依次向后计算的, 即每一个进入到Output Head 层的隐层输出都会到下一个MTP作为输入. 因此, 对于从i到k的输入序列, ${h}_i^{\prime k}$作为输入, 在MTP的后续计算中, 得到对应的第k个token, 其预测公式为:
$$P_{i+k+1}^k=\operatorname{OutHead}\left(\mathbf{h}_i^k\right) .$$损失优化目标为:
$$\mathcal{L}_{\mathrm{MTP}}^k=\operatorname{CrossEntropy}\left(P_{2+k: T+1}^k, t_{2+k: T+1}\right)=-\frac{1}{T} \sum_{i=2+k}^{T+1} \log P_i^k\left[t_i\right],$$这里其实很好理解, 就是交错输入序列, 使得每一个输入的token的next token都有之对于, 并计算其交叉熵总值. 如图所示.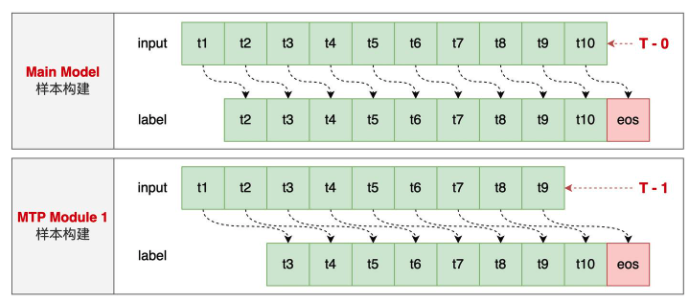
其中:
- 其中$T$表示输入序列长度,
- $t_{i}$表示第$i$位置的接地真相令牌,
- $P_{i}^{k}[t_{i}]$表示第$k$个MTP模块给出的$t_{i}$的相应预测概率。
最后, 计算所有深度的MTP损失平均值,并将其乘以加权系数λ,得到整体MTP损失$\mathcal{L}_{\mathrm{MTP}}$,
$$\mathcal{L}_{\mathrm{MTP}}^k = \frac{\lambda }{D}\sum_{k=1}^{D}\mathcal{L}_{\mathrm{MTP}}^k$$预测
- 传统模式: 当抛弃所有的MTP模块时, 可以当成正常的模型, 即传统LLM输出一个token的模式.
- 多token模式:
- 一次连续预测D个token. 第一个token由主模型预测, 剩下的由MTP模块预测.
- 加速token输出速度. 由于一次计算时, MTP模块比主模型的参数量小了很多. 从图中看仅有一层TRM, 而主模型为堆叠的TRM层, 为TRM * L, 因此, 每次连续的D个token预测, 计算量可以看成减少了TRM * (L - 1) * D.