模型加载方式
模型并行(Model Parallelism)
当你有一个单卡装不下的大模型时,把模型分割成不同的层,每一层都放指定的GPU上. 此时,模型做一轮forward和backward的过程如下: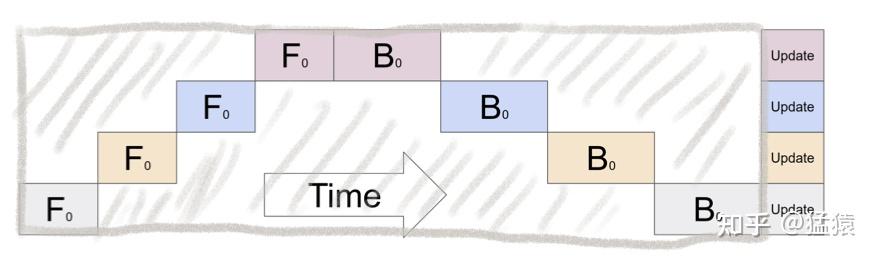
这张图的含义是:我在GPU0上做完一次forward,然后将GPU0上最后一层的输入传给GPU1,继续做forward,直到四块GPU都做完forward后,我再依次做backward。等把四块GPU上的backward全部做完后,最后一个时刻我统一更新每一层的梯度。
这样做确实能训更大的模型了,但也带来了两个问题:
1.GPU利用度不够。
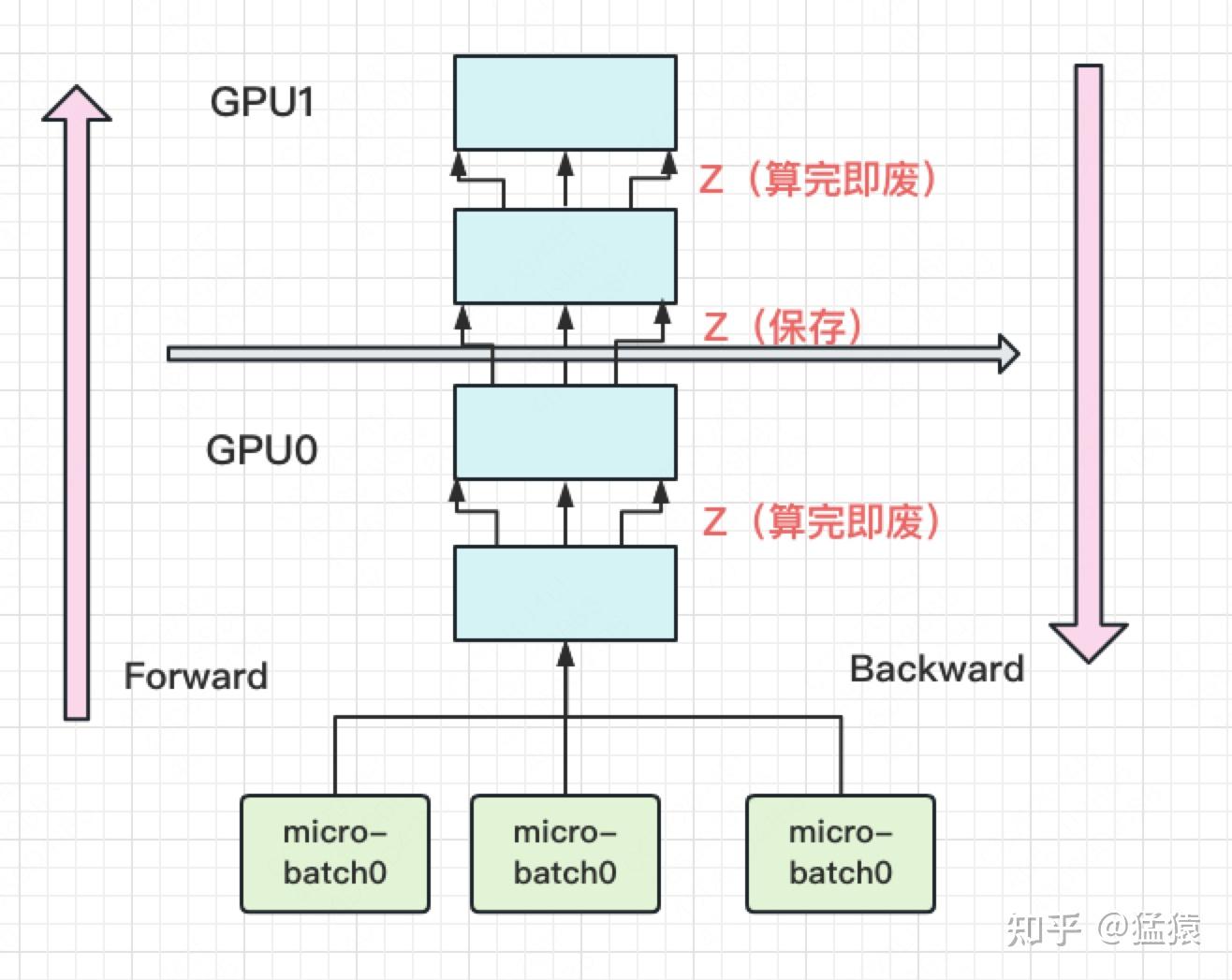
2.中间结果占据大量内存。在做backward计算梯度的过程中,我们需要用到每一层的中间结果z, 每一层的中间结果的保留随, 着模型的增大占据的显存也越大。
流水线并行(Pipeline Parallelism)
为了解决模型并行带来的问题, 而Gpipe提出了流水线并行. 流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练。未划分前的数据,叫mini-batch。在mini-batch上再划分的数据,叫micro-batch。
切分micro-batch
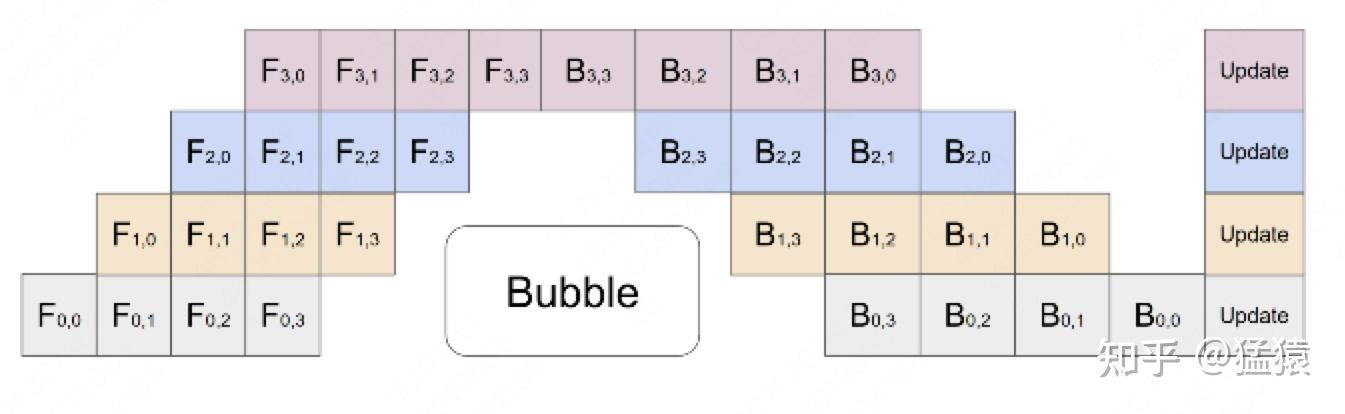
re-materalization(active checkpoint)
数据并行(Data Parallelism)
数据并行的核心思想是:在各个GPU上都拷贝一份完整模型,各自吃一份数据,算一份梯度,最后对梯度进行累加来更新整体模型。如下图所示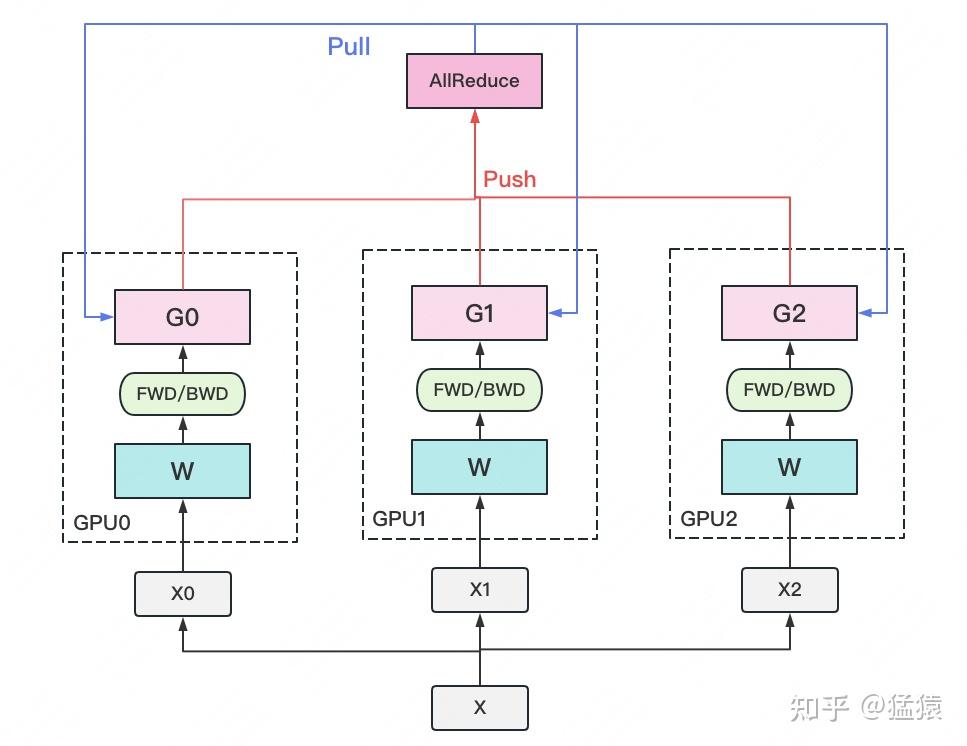
一个经典数据并行的过程如下:
1.在每块计算GPU上都拷贝一份完整的模型参数。额外指定一块GPU做梯度收集
2.把一份数据X(例如一个batch)均匀分给不同的计算GPU。
3.每块计算GPU做一轮Forward和Back Forward后,算得一份梯度 G。
4.每块计算GPU将自己的梯度push给梯度收集GPU,做聚合操作。这里的聚合操作一般指梯度累加。当然也支持用户自定义。
5.梯度收集GPU聚合完毕后,计算GPU从它那pull下完整的梯度结果,用于更新模型参数W。更新完毕后,计算GPU上的模型参数依然保持一致。
6.聚合再下发梯度的操作,称为AllReduce。
通讯瓶颈与梯度异步更新
实际操作中带来两个问题
存储开销大。每块GPU上都存了一份完整的模型,造成冗余。
通讯开销大。Server需要和每一个Worker进行梯度传输。当Server和Worker不在一台机器上时,Server的带宽将会成为整个系统的计算效率瓶颈。
受通讯负载不均的影响,DP一般用于单机多卡场景。
分布式数据并行(Distributed Data Parallel)
DDP首先要解决的就是通讯问题:将Server上的通讯压力均衡转到各个Worker上。 实现这一点后,可以进一步去Server,留Worker。
目前最通用的AllReduce方法:Ring-AllReduce, 它由百度最先提出,非常有效地解决了数据并行中通讯负载不均的问题,使得DDP得以实现。
Ring-AllReduce通过定义网络环拓扑的方式,将通讯压力均衡地分到每个GPU上,使得跨机器的数据并行(DDP)得以高效实现。
DDP把通讯量均衡负载到了每一时刻的每个Worker上,而DP仅让Server做勤劳的搬运工。当越来越多的GPU分布在距离较远的机器上时,DP的通讯时间是会增加的。
DeepSpeed ZeRO,零冗余优化
假设现在是一个4卡, 来看看DDP和ZeRO在存储上的区别。
Zero1 优化器分片
DDP: 4 个一模一样的 optimizer 副本(完全冗余)
ZeRO-1: 1 个 optimizer 的“分布式实现”(按卡切片)
Zero2 梯度分片
在Zero-1的基础上,进一步优化梯度的存储。
DDP: 4 个一模一样的 梯度 副本(完全冗余)
ZeRO-2: 1 个 梯度 的“分布式实现”(按卡切片)
Zero3 参数分片
在Zero-2的基础上,进一步优化模型参数的存储。
假设GPU0: W1, GPU1: W2, GPU2: W3, GPU3: W4
⚡ Forward 某一层时
每张卡执行:AllGather(W1, W2, W3, W4)
得到:W = [W1, W2, W3, W4]
计算完毕后, GPU0卡, 保留 W1(本地分片), 释放 W2, W3, W4(非本地)
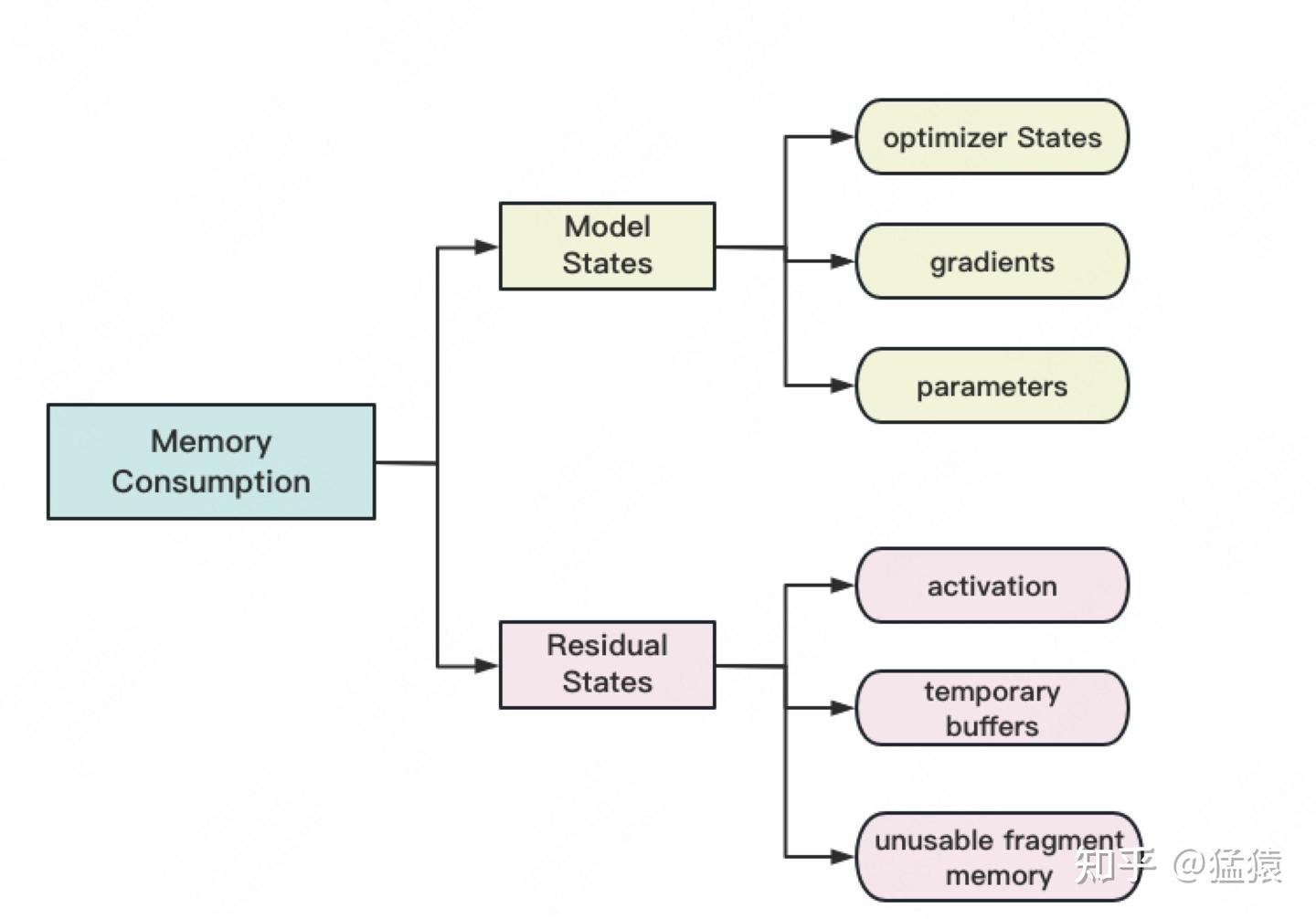
精度混合训练
在模型计算, forward和backward的过程中,fp32的计算开销也是庞大的。
那么能否在计算的过程中,引入fp16或bf16(半精度浮点数,存储占2byte),来减轻计算压力呢?
于是,混合精度训练就产生了,它的步骤如下图: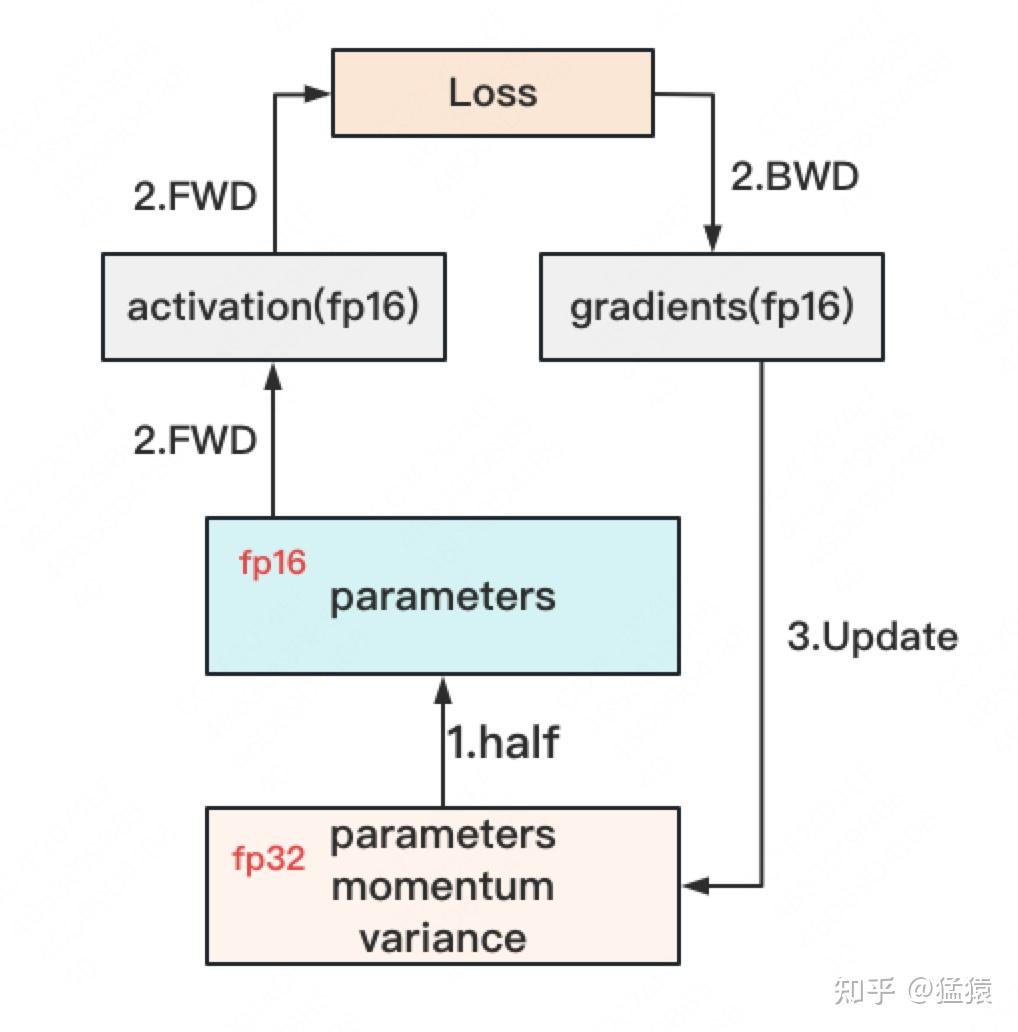
主要流程如下:
- 存储一份fp32的parameter,momentum和variance(统称model states)
- 在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter。
- 正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储。
- 用fp16 gradients去更新fp32下的model states。
- 当模型收敛后,fp32的parameter就是最终的参数输出。
通过这种方式,混合精度训练在计算开销和模型精度上做了权衡。