大模型工作流程
预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)的主要流程图如下图所示:
下面会分开介绍, 每个流程训练时, 所处理的数据, 以及loss等核心模块做了什么.
PT
数据
数据格式要求: 清洗过的大段连续文本即可, 如txt.
1第一章论
2传染病是指由病原微生物,如朊粒、病毒、衣原体、立克次体、支原体(mycoplasma)细菌真菌、螺旋体和寄生虫,如原虫、蠕虫、医学昆虫感染人体后产生的有传染性、在一定条件下可造成流行的疾病。感染性疾病是指由病原体感染所致的疾病,包括传染病和非传染性感染性疾病。
3传染病学是一门研究各种传染病在人体内外发生、发展、传播、诊断、治疗和预防规律的学科。重点研究各种传染病的发病机制、临床表现、诊断和治疗方法,同时兼顾流行病学和预防措施的研究,做到防治结合。
4传染病学与其他学科有密切联系,其基础学科和相关学科包括病原生物学、分子生物学、免疫学、人体寄生虫学、流行病学、病理学、药理学和诊断学等。掌握这些学科的基本知识、基本理论和基本技能对学好传染病学起着非常重要的作用。
5...
将文本全部拼接, 并按照 block_size = 1024进行分割. 将数据集最终处理成如下格式.
1训练数据集
2{
3 'input_ids': [116947, 67831, 114393, 104442, 67071, ..., 33108, 101304, 100178, 100645], # 1024长度
4 'attention_mask': [1, 1, 1, 1, 1, ..., 1, 1, 1, 1], # 1024长度
5 'labels': [116947, 67831, 114393, 104442, 67071, ..., 33108, 101304, 100178, 100645] # 1024长度
6}
其中:
input_ids: 字典对应的token, 训练时会根据其id在embedding层中找到其对应的权重.
attention_mask: 1表示该token是会被关注的信息, 0表示不关注. 在计算注意力分数softmax时,attention_mask为0的值将为0, 因此其他的信息会获得更多的关注.
labels: 用于预测时, 计算loss.
Loss
计算loss时, 对logits张量进行切片操作,去掉logits最后一维的最后一个元素, 同时去掉labels的第一个元素. 即构成一个序列对, 每一个词都有一个对应的下一个词.
因此, 当输入经过模型后, 为使总体损失降至最优, 可以理解为模型会优化每一个词的预测损失, 达到对输入的 next word|sentence predict.
1def ForCausalLMLoss(
2 logits, labels, vocab_size: int, num_items_in_batch: int = None, ignore_index: int = -100, **kwargs
3):
4 # Upcast to float if we need to compute the loss to avoid potential precision issues
5 logits = logits.float()
6 labels = labels.to(logits.device)
7 # Shift so that tokens < n predict n
8 shift_logits = logits[..., :-1, :].contiguous()
9 shift_labels = labels[..., 1:].contiguous()
10
11 # Flatten the tokens
12 shift_logits = shift_logits.view(-1, vocab_size)
13 shift_labels = shift_labels.view(-1)
14 # Enable model parallelism
15 shift_labels = shift_labels.to(shift_logits.device)
16 loss = fixed_cross_entropy(shift_logits, shift_labels, num_items_in_batch, ignore_index, **kwargs)
17 return loss
SFT
数据
数据格式要求: QA格式, 需一问一答.
1[
2 {
3 "from": "human",
4 "value": "两只脚明显大小不一样,腿也不一样粗,该怎么办,两只脚明显大小不一样,腿也不一样粗,该怎么办,需要做什么检查"
5 },
6 {
7 "from": "gpt",
8 "value": ",与走路姿势没有关系的,人的器官,没有完全对称的,只是有的不是很明显的,这很正常的,只要健康就好。只有手术能纠正的。"
9 }
10]
将问题与答案进行拼接, 这里按照模型输入长度对数据进行切分. 比如模型最大输入长度为8192.
将问答拼接后, 和PT流程一样, 区别在于, 在此阶段将所有问题部分进行-100标记, 转换数据格式如下. -100是为了使模型预测时, 只关注输出的内容.
1训练数据集
2{
3 'input_ids': [116947, 67831, 114393, 104442, 67071, ..., 33108, 101304, 100178, 100645], # 8192长度
4 'attention_mask': [0, 0, 0, 0, 0, ..., 1, 1, 1, 1], # 8192长度
5 'labels': [-100, -100, -100, -100, -100, ..., 33108, 101304, 100178, 100645] # 8192长度
6}
Loss
和PT阶段一样.
RM
数据
数据格式要求: 至少要给定三部分内容, 问题, 偏好答案, 弃用答案.
1{
2 "history":
3 [],
4 "question": "在这个任务中,你将会看到一个用中文提出的问题,有多个可能的答案。你需要根据你的常识知识,在"A""、"B"、"C"、"D"和"E"中选择一个最合适的选项。\n\n让我给你举个例子:问题:牙科诊所处理了很多口外伤的患者,这些患者来自哪里? \n选项:(A) 城镇 (B) 密西根 (C) 办公楼 (D) 医院 (E) 学校 \n这个例子的答案可能是:D\n原因是:这是正确答案,因为创伤性伤害通常由医院处理。\n\n好的,解决这个问题:\n问题:爱因斯坦认定能量是由什么构成的? \n选项:A 弱点 B 打球 C 大量 D 熵 E 事情 \n答案:",
5 "response_chosen": "当然,我很乐意帮忙!这是我的答案:\n\n正确答案是C) 大量。\n\n爱因斯坦的相对论表明,能量由大量的小粒子组成,比如光子和电子,它们是能量的基本单位。这个观点挑战了传统对能量作为单一统一物质的理解,而是提出能量由许多更小、更离散的组成部分构成。",
6 "response_rejected": "根据我的理解,这个问题的答案是\"B\" 打球。在物理学中,能量被定义为执行工作的能力。在这个语境中,\"能量\"(nenglian)可以被翻译为\"energy\"。\"爱因斯坦\"(Aìyīnésà)是一位著名的物理学家,他在相对论理论中引入了\"能量\"(nenglian)和\"强量\"(qīngliang)的概念。因此,\"能量\"(nenglian)由\"能\"(ne ng)表示\"力量\"或\"能力\",以及\"量\"(liang)表示\"数量\"或\"量\"组成。\"B\" 打球指的是以移动物体的形式存在的能量概念,具体来说是指球被球棒击中的形式。",
7 "system": ""
8}
进入模型的的输入格式如下:
1{
2 "input_ids_chosen": [[32, 6236, 1948, 264, 22208, 1196]],
3 "attention_mask_chosen": [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
4 "input_ids_rejected": [[32, 6236, 1948, 264, 22208, 1196]],
5 "attention_mask_rejected": [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
6}
Loss
为了使模型能够从众多选择中, 选取偏好的模型, 引入了推荐系统中常用的的 Pairwise Logloss.
可以看到, 将选择的答案和未选择的答案送入模型后, 分别计算得到了的 rewards_chosen_loss 和 rewards_rejected_loss
再利用 logsigmoid 进行期望优化, 不断调整直至输入模型后, 得到我们想要得到的 rewards_chosen.
1def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
2 rewards_chosen = model(input_ids=inputs["input_ids_chosen"],
3 attention_mask=inputs["attention_mask_chosen"])[0]
4 rewards_rejected = model(input_ids=inputs["input_ids_rejected"],
5 attention_mask=inputs["attention_mask_rejected"])[0]
6 # 计算损失:InstructGPT中的pairwise logloss https://arxiv.org/abs/2203.02155
7
8 loss = -torch.nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean()
9 if return_outputs:
10 return loss, {"rewards_chosen": rewards_chosen, "rewards_rejected": rewards_rejected}
11 return loss
Pairwise Logloss 在 RM 模型训练中的作用
1loss = -torch.nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean()
可以看到损失函数是-logsigmoid(A - B), 这个损失函数的本质是, 使模型能尽可能地将 rewards_chosen(A) 的值预测得比 rewards_rejected(B) 大。这样, Loss会逐渐越趋近于0。

DPO(Direct Preference Optimization)
DPO 是一种新的强化学习算法,它通过直接优化偏好(即对比反馈)来训练模型,而非传统的奖励函数。这意味着 DPO 在训练过程中使用的是正向和负向反馈信息,而非绝对奖励值,这样能更加直接地从人类反馈中学习。
优点:
- 高效的反馈学习:DPO 能更直接地利用人类反馈,尤其是在没有明确奖励函数的情况下,依赖用户的偏好进行优化。这使得它在处理开放式任务、长远规划任务等问题时有较大优势。
- 灵活性:DPO 不依赖于奖励函数的明确设定,可以更灵活地适应多种不同类型的任务和环境。
缺点:
- 需要大量的标注数据:DPO 需要人类偏好的标注数据,这在某些应用场景中可能是一个限制。
- 样本效率问题:尽管能够通过偏好学习减少一些训练难度,但在某些情况下,DPO 可能仍然需要大量样本才能充分优化。
DPO的实现:
- 直接优化 LM 来对齐人类偏好,无需建模 reward model 和强化学习阶段。基于 RL 的目标函数可以通过优化二分 cross entropy 目标来优化。
- 数据格式要求: 和RM阶段使用数据类似, 至少要给定三部分内容, 问题, 偏好答案, 弃用答案.
- 与之前的不一样, 走强化学习的方式来优化目标Loss, 训练器不再使用 transformer.Trainer, 而是使用 trl.*Trainer, 如trl.DPOTrainer.
相应的, 经过DPOTrainer 提供的 def tokenize_row()数据处理方法, 将数据处理成如下格式:
数据
1{
2 "prompt": ["<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n\n<|im_start|>user\n在这个任务中,你将.....,E 事情 \n答案:"],
3 "chosen": ["当然,我很乐意帮忙!这是我的答案:\n\n正确答案是C) 大量。\n\n爱因斯坦的相对论表明,能量由大量的小粒子组成,比如光子和电子,它们是能量的基本单位。这个观点挑战了传统对能量作为单一统一物质的理解,而是提出能量由许多更小、更离散的组成部分构成。"],
4 "rejected": ["根据我的理解,这个问题的答案是\"B\" 打球。在物理学中,能量被定义为执行工作的能力。在这个语境中,\"能量\"(nenglian)可以被翻译为\"energy\"。\"爱因斯坦\"(,。\"B\" 打球指的是以移动物体的形式存在的能量概念,具体来说是指球被球棒击中的形式。"],
5 "chosen_input_ids": [[151645, 151644, 8948, 198, 2610, 525, 264, 10950, 17847, ..., 104384, 1773, 151645]],
6 "chosen_attention_mask": [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ..., 1, 1, 1]],
7 "chosen_labels": [[ -100, -100, -100, -100, -100, -100, -100, -100, -100, ..., 104384, 1773, 151645]],
8 "rejected_input_ids": [[151645, 151644, 8948, 198, 2610, 525, 264, 10950, 17847, ..., 100414, 1773, 151645]],
9 "rejected_attention_mask": [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ..., 1, 1, 1]],
10 "rejected_labels": [[ -100, -100, -100, -100, -100, -100, -100, -100, -100, ..., 100414, 1773, 151645]],
11 "prompt_input_ids": [[151645, 151644, 8948, 198, 2610, 525, 264, 10950, ..., 17847, 77091, 198]],
12 "prompt_attention_mask": [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ..., 1, 1, 1]]
13}
DPOTrainer需要的数据结构变化如下, 但实际上和RM阶段需要的数据一样, 仅仅是结构变化了.
最终进入模型时, 数据结构如下.
1{"concatenated_input_ids":[[151645,151644,8948,198,2610,525,264,10950,17847,..., 104384, 1773, 151645],
2 [151645,151644,8948,198,2610,525,264,10950,17847,..., 104384, 1773, 151645]],
3
4"concatenated_attention_mask":[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ..., 1, 1, 1],
5 [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ..., 1, 1, 1]],
6
7"concatenated_labels":[[ -100, -100, -100, -100, -100, -100, -100, -100, -100, ..., 100414, 1773, 151645],
8 [ -100, -100, -100, -100, -100, -100, -100, -100, -100, ..., 100414, 1773, 151645]]}
Loss
DPO的优化目标, 公式:
$$\mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)=-\mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_\theta\left(y_w \mid x\right)}{\pi_{\mathrm{ref}}\left(y_w \mid x\right)}-\beta \log \frac{\pi_\theta\left(y_l \mid x\right)}{\pi_{\mathrm{ref}}\left(y_l \mid x\right)}\right)\right]$$出自论文: Direct Preference Optimization: Your Language Model is Secretly a Reward Model
由于不需要reward model, 仅仅使用一个模型, 通过对偏好数据和拒绝数据得到模型的对数概率, 最终进行对数值的loss值的计算. 可以看到dpo_loss计算时, 可以采用不同的loss计算方式, 默认损失计算方式为sigmoid.
代码片段
只列出了最核心的部分, 具体细节可以看源码: https://github.com/huggingface/trl/blob/v0.9.4/trl/trainer/dpo_trainer.py#L1174
1def concatenated_forward(self, model, batch):
2 """
3 返回 模型预测的"选择", "拒绝"动作的对数概率与logits
4 """
5 ...
6 return (chosen_logps, rejected_logps, chosen_logits, rejected_logits)
7
8
9def get_batch_loss_metrics( self, model, batch):
10 """Compute the DPO loss and other metrics for the given batch of inputs for train or test."""
11 metrics = {}
12 (
13 policy_chosen_logps, # 模型预测的"选择"动作的对数概率
14 policy_rejected_logps, # 模型预测的"拒绝"动作的对数概率
15 policy_chosen_logits, # 模型预测的"选择"动作的logits
16 policy_rejected_logits, # 模型预测的"拒绝"动作的logits
17 policy_chosen_logps_avg, # 模型预测的"选择"动作的对数概率均值
18 ) = self.concatenated_forward(model, batch)
19
20 # 获取参考模型的预测结果
21 # 1. 如果批次数据中包含参考模型的预测结果,则直接使用
22 if (
23 "reference_chosen_logps" in batch
24 and "reference_rejected_logps" in batch
25 and self.args.rpo_alpha is not None
26 ):
27 reference_chosen_logps = batch["reference_chosen_logps"]
28 reference_rejected_logps = batch["reference_rejected_logps"]
29 else:
30 # 2. 否则
31 # 2.1 没有参考模型, 则使用加载的模型
32 (reference_chosen_logps, reference_rejected_logps, _, _, _,) = self.concatenated_forward(self.model, batch)
33 # 2.2 使用参考模型进行预测
34 (reference_chosen_logps, reference_rejected_logps, _, _, _,) = self.concatenated_forward(self.ref_model, batch)
35
36 # 计算DPO损失和其他指标
37 losses, chosen_rewards, rejected_rewards = self.dpo_loss(
38 policy_chosen_logps,
39 policy_rejected_logps,
40 reference_chosen_logps,
41 reference_rejected_logps,
42 )
43
44 # 损失的
45 if self.args.rpo_alpha is not None:
46 losses = losses * self.args.rpo_alpha - policy_chosen_logps_avg
47
48 # 计算并存储各种指标
49 metrics[...] = ...
50 ...
51 return losses.mean(), metrics # 返回平均损失和指标字典
52
53
54def dpo_loss(self, policy_chosen_logps, policy_rejected_logps, reference_chosen_logps, reference_rejected_logps):
55 ...
56 return losses, chosen_rewards, rejected_rewards
PPO(Proximal Policy Optimization)
PPO 是一种基于策略梯度的强化学习算法,旨在通过限制更新步长来减少策略更新时的变化过大,从而提高稳定性。它通过"裁剪"目标函数来避免策略更新过快(从而导致训练的不稳定)。
PPO的工作
- 推出:语言模型根据查询生成响应。
- 评估:使用函数、模型、人工反馈或它们的某种组合来评估查询和响应。此过程应为每个查询/响应对生成一个标量值。
- 优化:在优化步骤中,查询/响应对用于计算序列中标记的对数概率。这是通过训练后的模型和参考模型完成的。两个输出之间的 KL 散度用作额外的奖励信号,以确保生成的响应不会偏离参考语言模型太远。然后使用 PPO 训练主动语言模型。
![PPO]()
![PPO]()
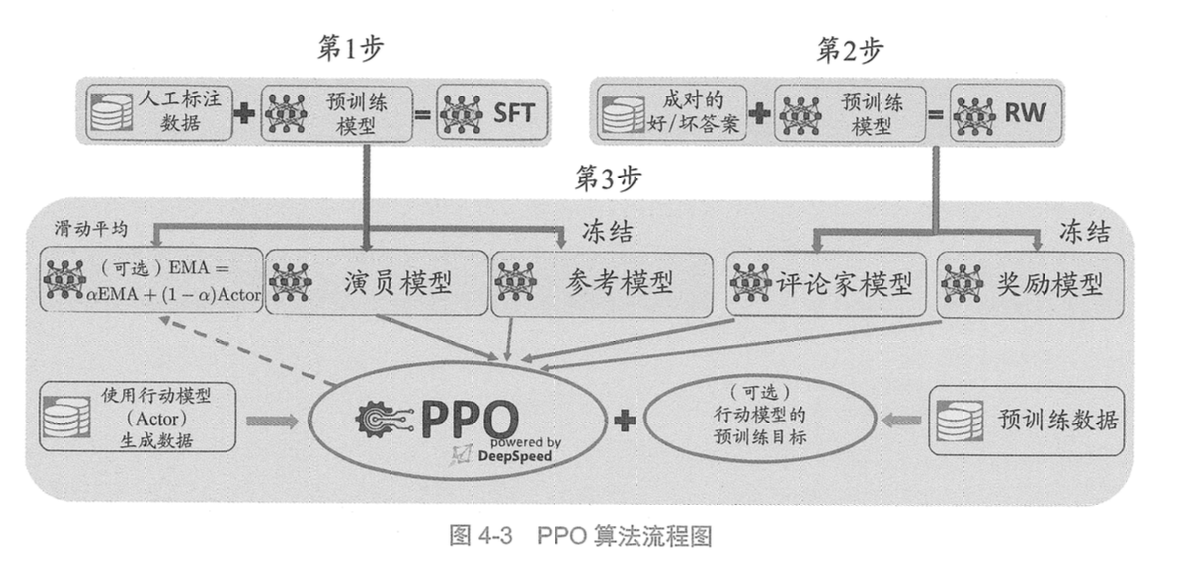
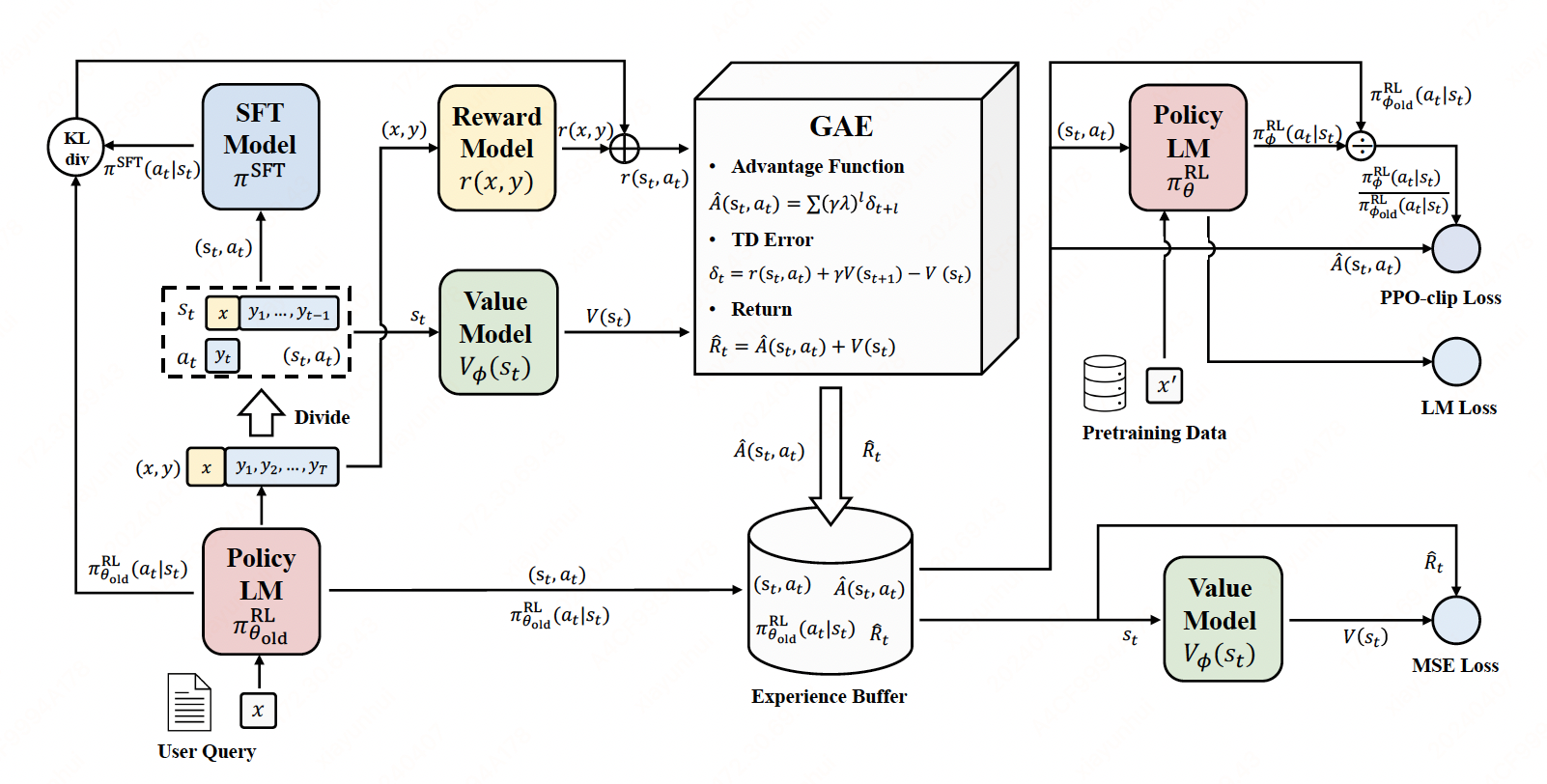
如上图,在RLHF-PPO阶段,一共有四个主要模型,分别是:
- 演员模型 Actor Model(红色):更新权重, SFT Model,数来源于RLHF过程中的第⼀步提前准备好的监督微调模型。该模型不仅参与训练,也是PPO过程中需要进⾏对齐的语⾔模型,它是我们强化学习训练的主要⽬标和最终输出。该模型被训练⽤来对齐⼈类偏好的模型,也被称为“策略模型”(policymodel)
- 评论家模型 Critic Model(绿色):更新权重, Reward Model(从RM初始化而来),数来源于先前训练好的奖励模型。模型参数参与反向传播,⽤来预测⽣成回复的未来累积奖励
- 参考模型 Reward Model(黄色):不更新权重, Reward Model,参数来源于RLHF过程中的第⼀步提前训练好的奖励模型。它的主要功能是输出奖励分数来评估回复质量的好坏
- 奖励模型 Reference Model(蓝色):不更新权重, SFT Model,它的作用是在训练过程中, 防止Actor训歪(朝不受控制的方向更新,效果可能越来越差), 通过KL散度, 衡量两个模型的输出分布尽可能的相似.
Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系,综合它们的结果计算loss,用于更新Actor和Critic Model
第一个阶段,经验采样
actor: 根据prompt数据集生成repsonse, 对于response中每一个token对应的log_prob记为log_probs。
reference: actor生成的 prompt+response 作为输入, 记录 prompt+response 的每个token的log_prob,记为ref_log_probs。
critic: reward模型根据prompt+response输出values和reward。
优点:
- 稳定性:PPO 通过对目标函数进行裁剪,避免了策略的过大更新,减少了训练过程中的不稳定性。
- 样本效率较高:相比于原始的强化学习算法(如REINFORCE),PPO 在样本效率上表现较好,能更快速地学习。
- 易于实现:PPO 是一种相对容易实现且表现稳健的算法,尤其适合用于复杂的环境中进行训练。
缺点:
- 适用场景限制:PPO 偏向于需要大量交互并且训练时间较长的任务,对于某些即时反馈或小样本场景可能表现不佳。
- 计算资源要求:尽管相比其他方法更为高效,但在处理大型问题时,仍然需要较为充足的计算资源。
同样的, RL训练器使用 trl.PPOTrainer.
数据
1{
2 "prompt": "Explain the theory of relativity.",
3 "response": "The theory of relativity was developed by Einstein...",
4 "reward": 0.78 // 模型、规则、人工打分
5}
Loss
具体代码实现: https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py#L500
GRPO(Generalized Reward Policy Optimization)
出自论文: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
GRPO优化过程中, 和PPO类似, 需要三个模型: Policy_model(优化模型), reference_model, reward_model.
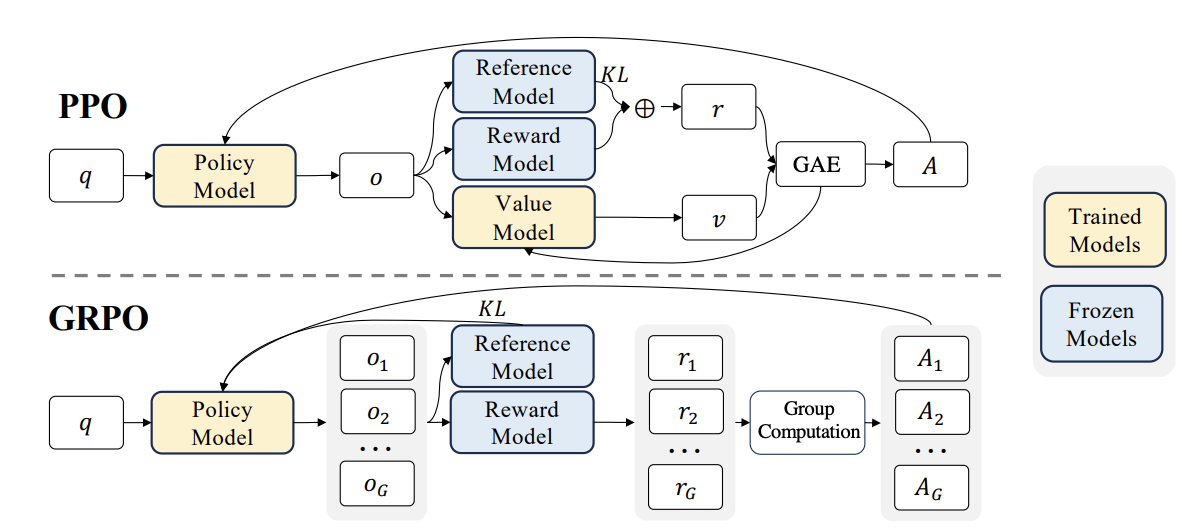
其中, 奖励的分值可以由规则来替代, 比如最后的答案为目标答案则给2分. 因此规则简单的情况下可以使用 reward_funcs 代替 reward_model. 若不担心模型训歪, reference_model也可以不使用, 因此最小仅需一个模型就可以使GRPO训练起来代码.
GRPO相对于PPO, 主要思路是:丢掉 KL 散度项 和 Value Model,改为同一个问题进行多个回答 具体流程大致为, 使用策略模型根据同一个prompt, 生成多个回答, 然后对所有回答进行 “group 内排名 + z-score 归一化”, 作为奖励信号.
1比如某个 prompt,我们生成了 4 个回答,reward model 给出分数是:
2[1.2, 0.7, 1.5, 0.9]
3
4计算标准化后的 z-score:
5mean = 1.075, std = 0.3 => z-scores = [0.42, -1.25, 1.42, -0.58]
6
7这些 z-score 就作为最终的 advantage 信号用于训练。
数据
GRPO的数据流大致如下.
1{
2 "prompt": "Explain the theory of relativity.",
3 "responses": [
4 "Relativity explains gravity as curvature of spacetime...",
5 "It talks about time dilation and length contraction...",
6 "It is a theory by Einstein involving E=mc^2..."
7 ],
8 "rewards": [0.85, 0.62, 0.71]
9}
DPO、PPO、GRPO 对比
| 方法 | 特点 | 数据格式 | 是否需要多个 response | 是否需要 reference model | 是否需要 reward model |
|---|---|---|---|---|---|
| PPO | 强调 reward 优化 | 单个 prompt + 单个 response + reward | ❌ | ✅ 是 | ✅ 是 |
| DPO | 偏好对比优化 | 单个 prompt + (chosen, rejected) | ❌ | ✅ 是 | ❌ 否 |
| GRPO | group 内排序优化 | 单个 prompt + 多个 response + 多个 reward | ✅ | ✅ 是 | ❌(可选) |
参考文章
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
OpenRLHF源码解析一PPO
Reinforcement Learning From Human Feedback