背景: 大模型进行推理或训练时, Attention计算是其中最核心的计算模块之一, 也是计算量最大的模块之一. 因此, 如何优化Attention的计算效率和性能, 是提升大模型整体性能的关键所在. Attention的计算过程涉及到大量的矩阵乘法和softmax操作, 当输入序列较长时, 计算过程会变得非常缓慢且耗费内存. 因此, 业界提出了几种加速方案, 包括FlashAttention、不同的Attention结构(如Multi-Query Attention、Group-Query Attention等)以及Page Attention等. 这些方法通过优化计算流程、减少内存访问次数以及改进Attention结构等方式, 来提高Attention的计算效率和性能. 当输入序列(sequence length)较长时, Transformer的计算过程缓慢且耗费内存,即计算的矩阵会变得很大, 这是因为self-attention的计算时间和内存存取复杂度会随着输入序列的增加成二次增长。因此业界提出了几种加速方案.
工程角度优化
FlashAttention
Attention标准实现没有考虑到对内存频繁的IO操作, 它基本上将HBM加载/存储操作视为0成本。内存不是一个单一的工件,它在本质上是分层的,一般的规则是:内存越快,越昂贵,容量越小。因此和木桶原理类似, 需要考虑到每个模块的瓶颈。
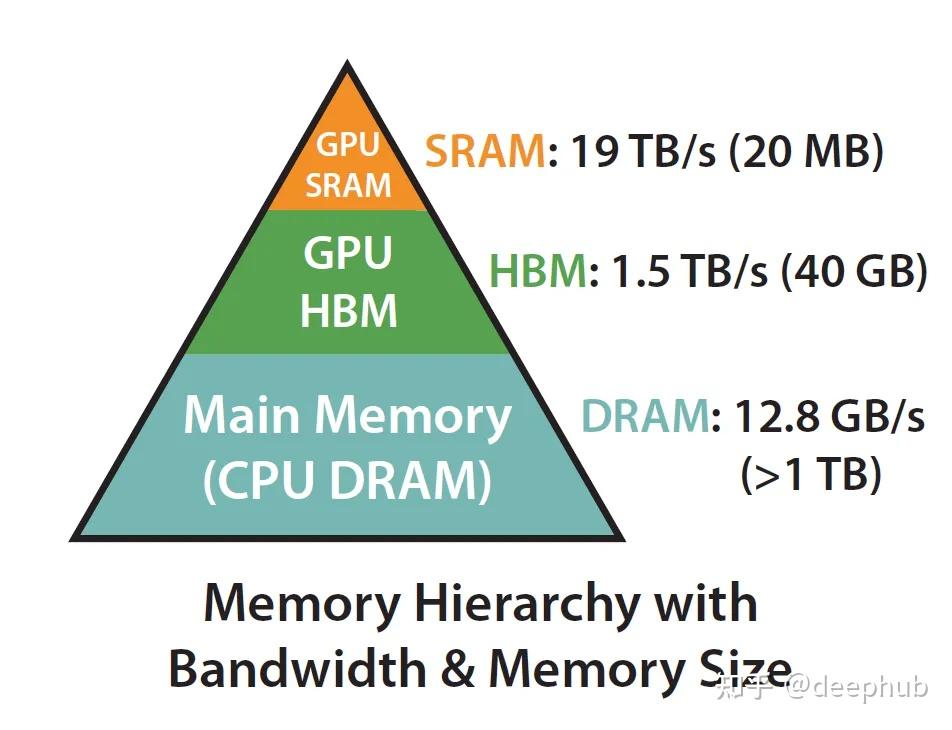
SRAM(Static Random Access Memory)是一种高速缓存内存,通常用于CPU和GPU的缓存层。它具有较低的访问延迟和较高的带宽,但成本较高,容量较小。SRAM的访问速度非常快,适合频繁访问的数据存储和计算操作。
HBM(High Bandwidth Memory)是一种高带宽的内存技术,通常用于GPU等高性能计算设备。它通过将多个DRAM芯片垂直堆叠,并使用高速接口与处理器直接连接,提供了极高的带宽和较大的容量。HBM适合存储大量数据,但访问速度相对较慢,适合大规模数据存储和传输。
这就导致了传统的Attention计算过程需要频繁地在SRAM和HBM之间进行数据传输, 这会带来显著的性能瓶颈。FlashAttention通过优化计算流程,减少了这种数据传输的次数,从而提高了整体的计算效率。因此FlashAttention的核心优化点在于减少内存访问次数,充分利用SRAM的高速性能,同时降低对HBM的依赖,从而实现更高效的Attention计算。
传统分块计算过程
例如原本的$QK^{T}$一次计算过程进行拆分, 分别将$Q$和$K^{T}$划分为为$m$,和$n$个小块, 然后依次将$m_{i}$和$n_{i}$小块计算的结果放置到指定的区域. 当然, 这样操作会带来额外的通讯次数的开销, 变成m * n, 但对于存储架构来说, SRAM与HBM的通信速率是非常快的, 在这里的通讯次数开销是可以接受的.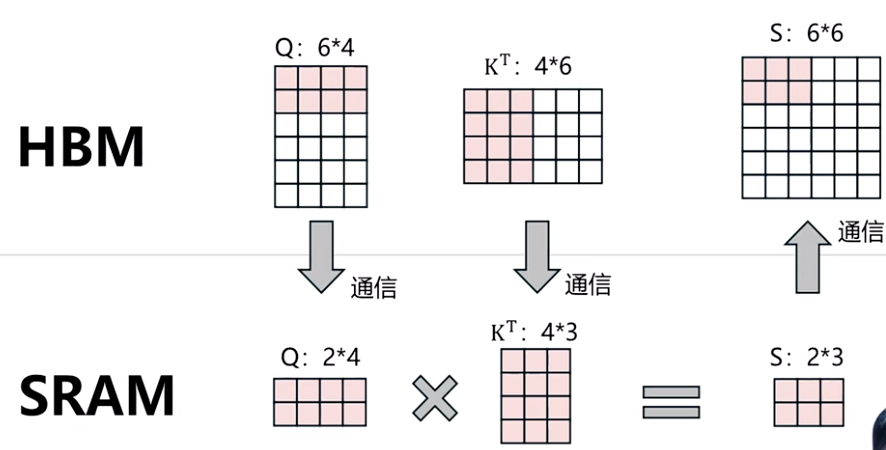
通信过程, 整个过程需要6次通信, 3次写入到SRAM, 3次到HBM中.
- 将矩阵 Q 和K从 HBM 分块加载到 SRAM 中
- 逐块计算 $S_{ij} = Q_{i}K_{j}^{T}$, 并将每个子矩阵计算得出的 $S_{ij}$ 从SRAM 写入HBM。
- 从 HBM 中加载所需的子矩阵 $S_{ij}$ 到 SRAM 中,为后续 softmax计算做准备。
- 对每个子矩阵 $S_{ij}$ 计算 softmax,得到$P_{ij}= softmax( S_{ij})$,并将每个子矩阵 $P_{ij}$从 SRAM 写入 HBM。
- 将矩阵 P和V从 HBM 分块加载到 SRAM 中。
- 将P和V分成较小的块,逐块计算 $O_{ij} =P_{i}V_{j}$,并将每个子矩阵 $O_{ij}$ 从 SRAM 写入 HBM.
FlashAttention的改进
FlashAttention改进了计算过程, 所有计算过程统一在SRAM中计算, 将最终的计算结果返回给HBM, 只进行一次读写. 其过程如下.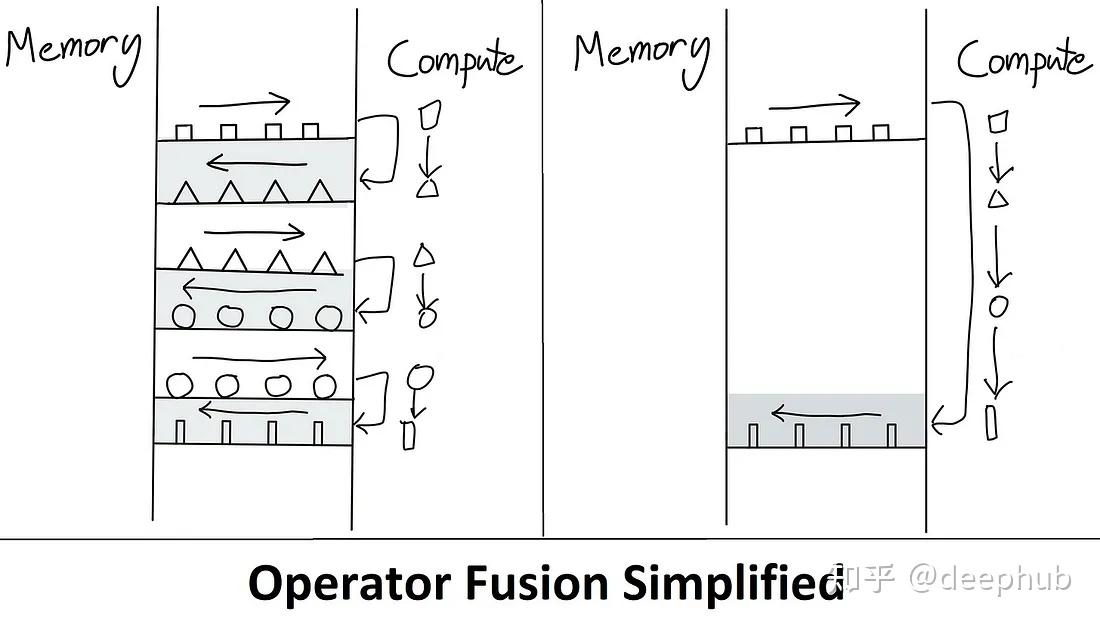
online-softmax 分块计算原理
原本softmax 需要先计算出所有的$S_{ij}$, 然后再进行softmax计算, 但是FlashAttention的online-softmax算法, 通过分块计算的方式, 在每个块计算完之后就进行softmax计算, 并且在计算过程中维护一个全局的最大值和指数和, 来保证数值稳定性. 具体来说, 在每个块计算完之后, 会更新全局的最大值和指数和, 以便在下一个块计算时使用. 这样做不仅可以节约内存带宽,还可以提高计算效率. 核心公式如下:
$𝑚_{𝑛𝑒𝑤}=max(𝑚_{𝑜𝑙𝑑}−𝑚_{c})$
$𝑙_{𝑛𝑒𝑤}=𝑙_{𝑜𝑙𝑑} ·𝑒^{(𝑚_{𝑜𝑙𝑑}−𝑚_{𝑛𝑒𝑤} )}+𝑙_{c} ·𝑒^{(𝑚_{c}−𝑚_{𝑛𝑒𝑤} )}$
其中:
- $𝑚_{𝑐}$: 当前块最大值
- $𝑚_{𝑜𝑙𝑑}$: 当前全局最大值
- $𝑙_{𝑐}$: 当前块局部指数和
- $𝑙_{𝑜𝑙𝑑}$: 当前全局分母 指数和
详细计算原理示例及讲解: 小红书: 图解Flash Attention核心原理

Page Attention
由于传统申请连续内存的方式在处理长序列时会导致内存碎片化和性能下降, Page Attention通过将内存划分为固定大小的页面(pages), 并使用虚拟地址空间来管理这些页面的访问和存储, 这种机制允许模型在处理长序列时, 可以更灵活地管理内存资源, 从而提高计算效率和性能.
具体来说, Page Attention通过将输入序列划分为多个页面(pages), 每个页面可以独立地进行Attention计算, 并且通过虚拟地址空间来管理这些页面的访问和存储. 这样做不仅可以减少内存的使用, 还可以提高模型在处理长序列时的效率和性能.
示例及详解 https://zhuanlan.zhihu.com/p/9632325957
算法角度优化
共享 KV 的思路
多个Head共享使用1组KV,将原来每个Head一个KV,变成1组Head一个KV,来压缩KV的存储。代表方法:GQA,MQA等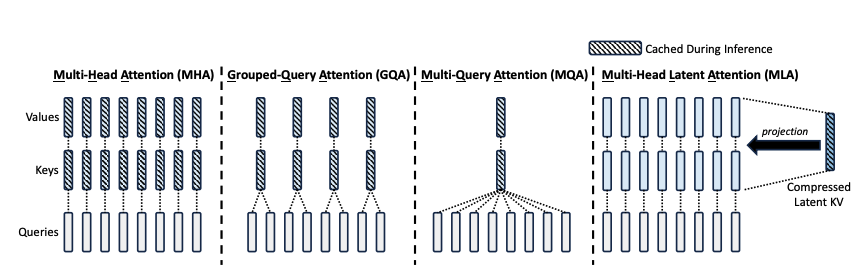
Multi-Head Attention
图1, 每一层的所有Head都独立拥有自己的KQV权重矩阵, 计算时各自使用自己的权重计算.
Multi-Query Attention
图2, 每一层的所有Head,按照数量分组, 一组的成员, 在计算Attention时, KV权重矩阵是共享的, 只有Q权重矩阵是独立的.
例如每个Head中的Q权重矩阵是独立的, 但每组的Q权重共享一组KV权重矩阵, 这样就减少了KV的存储, 当然也会损失一定的性能. 比如原来MHA的Head有8个KQV权重矩阵, 现在进行分组后, 每两个Q权重矩阵共享一组KV权重矩阵, 则现在每个Head8个Q权重矩阵, 但只有4个KV权重矩阵, KV的存储就减少了一半.
Group-Query Attention
图3, 每个Head的Q权重矩阵是独立的, 但所有Head共享一组KV权重矩阵, 这样就进一步减少了KV的存储, 当然也会损失更多的性能. 比如原来MHA的Head有8个KQV权重矩阵, 现在进行分组后, 每个Head8个Q权重矩阵, 但只有1个KV权重矩阵, KV的存储就减少了7/8.
一些推导
输入$X$在一个Head得到的矩阵为$Q, K, V$, 假设Head数量为4, 分组数量G为2, 现在我们得到的矩阵如下:
| $Q$权重矩阵 | $K$权重矩阵 | $V$权重矩阵 |
|---|---|---|
| $Q_1, Q_2, Q_3, Q_4$ | $K_1, K_1, K_2, K_2$ | $V_1, V_1, V_2, V_2$ |
而实际在multi-head attention中, 多个head的 $Q$ 矩阵, 其得到可以由一次计算得出
$Q=\left[Q_1, Q_2, Q_3, Q_4\right]=XW^{Q}, W^{Q} \in R^{d \times\left(d_k \times h\right)}$
其中K的计算会稍微复杂一些, 因为每个Head的K权重矩阵是共享的, 但不同组的K权重矩阵又不共享, 因此需要先计算出每组的K矩阵, 然后再将其复制到对应的Head中. 其中:
$$K_{\downarrow}=\left[K_1, K_2\right]=XW^{K}, W^{K} \in R^{d \times\left(d_k \times n\right)}$$因此$XW^{K}$权重矩阵的维度是$d \times\left(d_k \times n\right)$, 其中n是分组数量, 每组对应一个K权重矩阵. 然后将每组的K矩阵复制到对应的Head中, 得到最终的K矩阵为:
$$ K=\left[K_1, K_1, K_2, K_2\right]=\left[K_1, K_2\right]\left[\begin{array}{rrrr} I_{d_k} & I_{d_k} & 0 & 0 \\ 0 & 0 & I_{d_k} & I_{d_k} \end{array}\right] $$整个计算过程表达式可以表示为:
$$ K=XW^{K} \left[\begin{array}{rrrr} I_{d_k} & I_{d_k} & 0 & 0 \\ 0 & 0 & I_{d_k} & I_{d_k} \end{array}\right]\\ =XW^{K}_{\uparrow} $$$V$的计算过程和K一样, 整理一下, 我们现在得到了:
$$K=XW^{K}_{\uparrow}, V=XW^{V}_{\uparrow}$$这部分也可以合并起来一次计算, 我们将KV其权重矩阵拼接得到:
$$ XW^{KV} = [K_{\downarrow}, V_{\downarrow}] = \left[K_1, K_2, V_1, V_2\right] W^{KV} , W^{KV} \in R^{d \times\left(d_k n_g+d_v n_g\right)}$$同理, 再乘以一个拼接的复制矩阵, 得到最终的K和V矩阵:
$$XW_{\uparrow}^{KV} = \left[K_1, K_2, V_1, V_2\right]\left[\begin{array}{rrrr} I_{d_k} & I_{d_k} & 0 & 0 \\ 0 & 0 & I_{d_k} & I_{d_k} \\ I_{d_v} & I_{d_v} & 0 & 0 \\ 0 & 0 & I_{d_v} & I_{d_v} \\ \end{array}\right]\\$$Multi-Head Latent Attention
MLA由GQA和GQA的基础上发展而来, 其核心思想是将每个Transformer层的KV权重矩阵分解成两个低秩矩阵, 其中一个矩阵是输入序列的线性变换, 另一个矩阵是一个小的可学习参数矩阵. 这样做的好处是可以大幅减少KV权重矩阵的存储需求, 同时保持较好的性能. 其架构图如下:
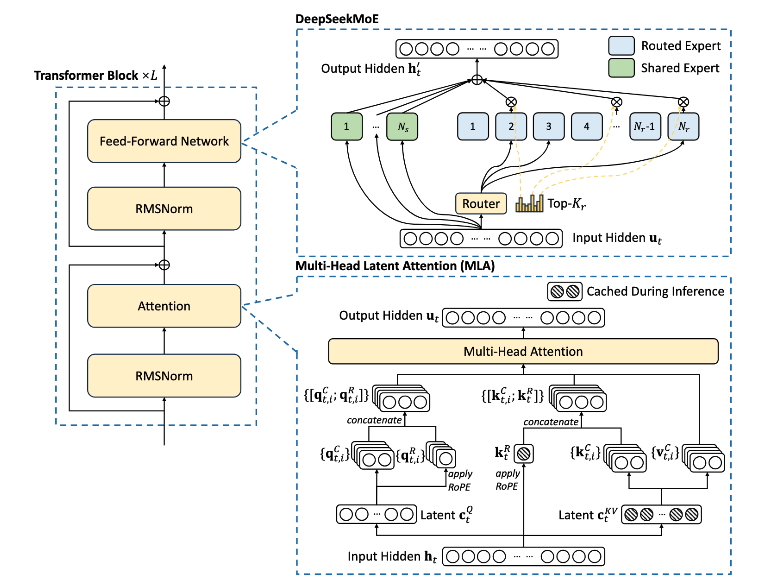
一些推导
$$ C^{KV} = XW^{KV}_{\downarrow},其中W^{KV}_{\downarrow} \in R^{d \times d_c }$$这里的$C^{KV}$是输入序列的线性变换矩阵.
通过分解得到 $C^{KV} = C^{K}C^{V}$, 其中$C^{K}$是输入序列的线性变换矩阵, $C^{V}$是一个小的可学习参数矩阵.
$W_{\uparrow}^{K}$ 和 $W_{\uparrow}^{V}$ 是两个小的可学习参数矩阵, 其维度分别为 $d_c \times d_k$ 和 $d_c \times d_v$ .
同样的, MLA查询矩阵$Q$也同样使用低秩压缩技术. $XW^{Q} = W^Q_{\downarrow}W^Q_{\uparrow}$,
最终的$Q$, $K$ 和 $V$ 矩阵:
$$ Q = W^Q_{\downarrow}W^Q_{\uparrow} $$$$ K=C^{KV}W^{K}_{\uparrow}=XW^{KV}_{\downarrow}W^{K}_{\uparrow} $$$$ V=C^{KV}W^{V}_{\uparrow}=XW^{KV}_{\downarrow}W^{V}_{\uparrow} $$$$ \begin{aligned} \delta X &= OW^{O} \\ & = [O_1, O_2, O_3, ..., O_h]W^O \\ & = [..., \frac{Softmax(Q_{i}K_{i}^{T})}{\sqrt{d_k}}V_{i},...]W^O \\ & = [..., \frac{Softmax(XW^Q_{\downarrow, i} W^Q_{\uparrow, i} {W^K_{\uparrow, i}}^{T} {C^{KV}}^{T})}{\sqrt{d_k}}V_{i},...]W^O \\ & \\ & 将 softmax的计算用 A_{i} 表示, 则上式可以表示为: \\ & \\ & = [..., A_{i}V_{i},...]W^O \\ & = [..., A_{i}C^{KV}W^{V}_{\uparrow, i},...]W^O \\ & \\ & 这里还假设 是4个Head的Attention, 则上式可以表示为与对角线矩阵的乘积: \\ & \\ & = \left[A_1 C^{KV}, A_2 C^{KV}, A_3 C^{KV}, A_4 C^{KV}\right]\left[\begin{array}{rrrr} W^V_{\uparrow, 1} & 0 & 0 & 0 \\ 0 & W^V_{\uparrow, 2} & 0 & 0 \\ 0 & 0 & W^V_{\uparrow, 3} & 0 \\ 0 & 0 & 0 & W^V_{\uparrow, 4} \\ \end{array}\right] W^O \\ \end{aligned} $$$A_{i}C^{KV}$, 将外投影矩阵$C^{KV}$投影到$A_{i}$, 对角线矩阵可以投影整合进$W^O$中, 即整合进$Q$与$O$的计算中, 从而使Attention计算高效而无需额外计算.
对ROPE的兼容
ROPE对$Q$, $K$做位置旋转时, 是乘以一个旋转矩阵的(下面我们表示为$R$), 那么公式如果直接进行旋转位置编码的计算, 则会由:
$$XW^Q_{\downarrow, i} W^Q_{\uparrow, i} {W^K_{\uparrow, i}}^{T} {C^{KV}}^{T}$$变成:
$$XW^Q_{\downarrow, i} W^Q_{\uparrow, i} R_m R_n^{T} {W^K_{\uparrow, i}}^{T} {C^{KV}}^{T}$$这样会导致上投影矩阵 $Q$ 与 $V$ 被阻隔了, 导致推理时无法合并 ${W^K_{\uparrow, i}}^{T}$ 上投影矩阵, 这就导致在推理时, 必须重新计算所有历史token的$K$, 从而显著降低推理效率.
MLA通过增加了多头查询并使用共享K来解决这个问题, 通过 Partial RoPE 来进行解耦.
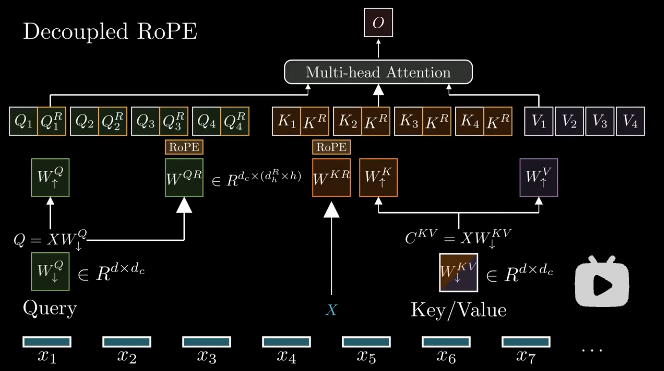
如图所示, 将原始查询$Q$ 与 旋转后的 $Q^{R}$ 进行拼接, K也同样进行拼接, 这样就使得旋转位置编码的计算只作用于 $Q$ 上, 而不会阻隔上投影矩阵的计算, 从而使得推理时可以合并 ${W^K_{\uparrow, i}}^{T}$ 上投影矩阵, 从而避免了重新计算所有历史token的$K$.
Lighting Indexer
随着token数量的增加, 后面的token需要和前面所有的token计算Attention, 计算关联度, 从而导致计算量增加. 因此DeepSeek V3提出了Lighting Indexer, 其核心是快速评估各标记的关联性, 仅筛选出最相关的token进行注意力计算. 这就是 DeepSeek Sparse Attention(DSA) 的核心思想.
其计算方式和Attention计算方式类似, 也是通过计算查询和键之间的相关性来评估token的关联性. 具体来说, Lighting Indexer会计算每个查询与所有键之间的相关性分数, 然后根据这些分数筛选出最相关的token进行Attention计算.
$$q_t = x_t W^Q_{\downarrow}$$$$[q^t_1, q^t_2, q^t_3, q^t_4] = q_t W^Q_{\uparrow}$$$$ K = X W^K $$$$ w^t_1 ReLU(q^t_1 · k^s)$$最终对所有的求和, 得到索引评分.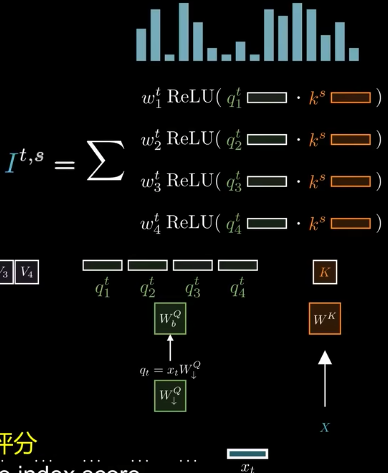
TODO 哈达玛变化优势
最终, DSA能够实现长序列2-3倍的加速, 内存占用还能减少 30% ~ 40%, 关键是提升效率的同时, 同时保持与全注意力机制相当的性能. 这使得DeepSeek V3在处理长序列时具有显著的效率优势.
训练过程
- 先冻结主模型的多头注意力层, 仅更新Lightning 索引器参数. 构建目标分布时, 首先对每个 query token,在所有注意力头(attention heads)上的主要注意力分数进行求和, 再沿序列维度做误差归一化, 通过密集预热阶段(warm up), 将索引器的输出调整至与主注意力分布一致.
- 系统会
⭐️推荐观看, 可视化讲解, https://www.bilibili.com/video/BV17QSpBDEHG
参考地址
[1] deepseek-v2
[2] deepseek-v3
[3] deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention)
[4] 知乎: FlashAttention算法详解