背景: 当输入序列(sequence length)较长时, Transformer的计算过程缓慢且耗费内存,即计算的矩阵会变得很大, 这是因为self-attention的计算时间和内存存取复杂度会随着输入序列的增加成二次增长。因此业界提出了几种加速方案.
FlashAttention
Attention标准实现没有考虑到对内存频繁的IO操作, 它基本上将HBM加载/存储操作视为0成本。因此FlashAttention的优化方案是通过“split attention”的方式, 将多个操作融合在一起, 只从HBM加载一次,然后将结果写回来。减少了内存带宽的通信开销,并且采用了高效的GPU实现, 极大地提高了效率。
核心:用分块softmax等价替代传统softmax。
优点:节约HBM,高效利用SRAM,省显存,提速度。
传统分块计算过程
例如原本的$QK^{T}$一次计算过程进行拆分, 分别将$Q$和$K^{T}$划分为为$m$,和$n$个小块, 然后依次将$m_{i}$和$n_{i}$小块计算的结果放置到指定的区域. 当然, 这样操作会带来额外的通讯次数的开销, 变成m * n, 但对于存储架构来说, SRAM与HBM的通信速率是非常快的, 在这里的通讯次数开销是可以接受的.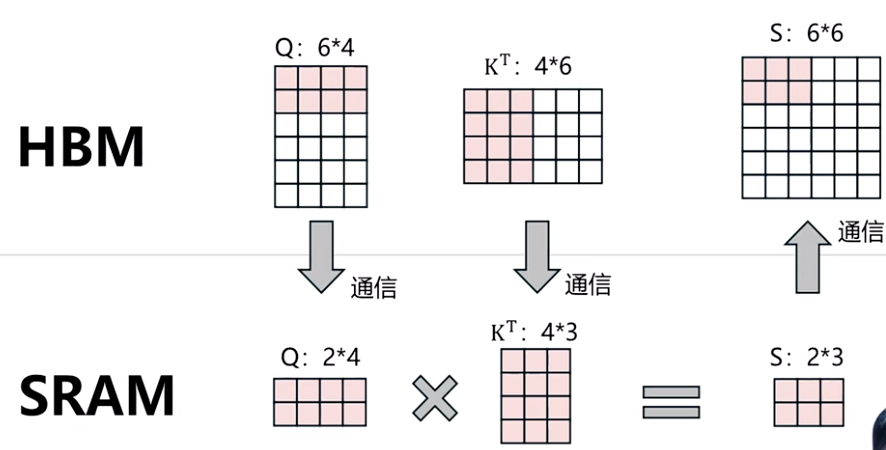
通信过程, 整个过程需要6次通信, 3次写入到SRAM, 3次到HBM中.
- 将矩阵 Q 和K从 HBM 分块加载到 SRAM 中
- 逐块计算 $S_{ij} = Q_{i}K_{j}^{T}$, 并将每个子矩阵计算得出的 $S_{ij}$ 从SRAM 写入HBM。
- 从 HBM 中加载所需的子矩阵 $S_{ij}$ 到 SRAM 中,为后续 softmax计算做准备。
- 对每个子矩阵 $S_{ij}$ 计算 softmax,得到$P_{ij}= softmax( S_{ij})$,并将每个子矩阵 $P_{ij}$从 SRAM 写入 HBM。
- 将矩阵 P和V从 HBM 分块加载到 SRAM 中。
- 将P和V分成较小的块,逐块计算 $O_{ij} =P_{i}V_{j}$,并将每个子矩阵 $O_{ij}$ 从 SRAM 写入 HBM.
FlashAttention的改进
FlashAttention改进了计算过程, 所有计算过程统一在SRAM中计算, 将最终的计算结果返回给HBM, 只进行一次读写. 其过程如下.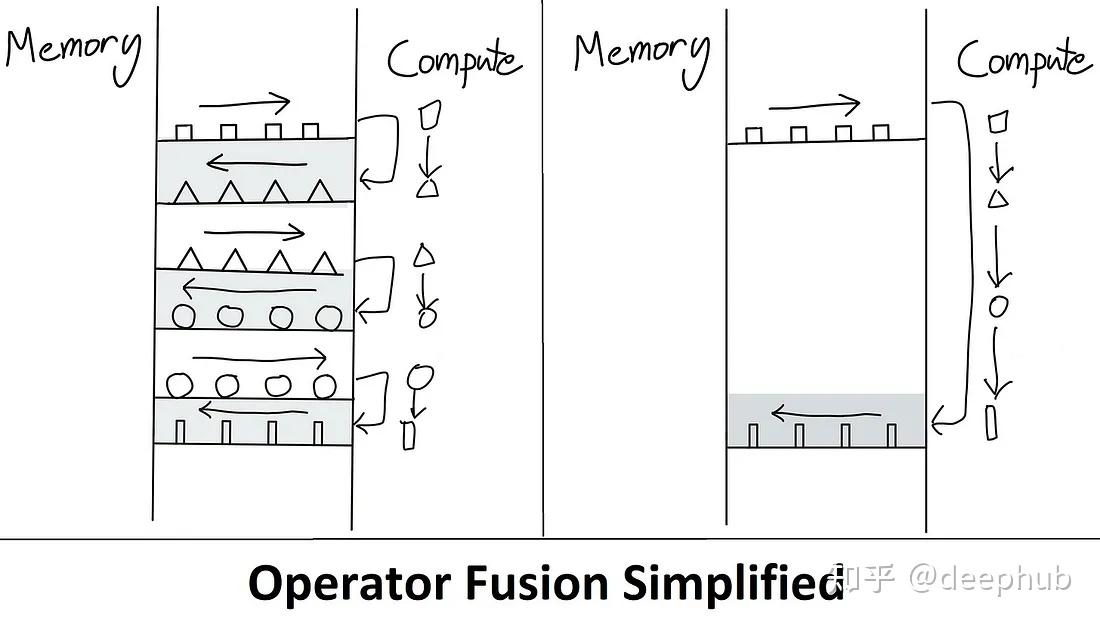
safe-softmax分块计算过程
查看详细计算过程: 小红书: 图解Flash Attention核心原理
相关内容补充
内存不是一个单一的工件,它在本质上是分层的,一般的规则是:内存越快,越昂贵,容量越小。因此和木桶原理类似, 需要考虑到每个模块的瓶颈。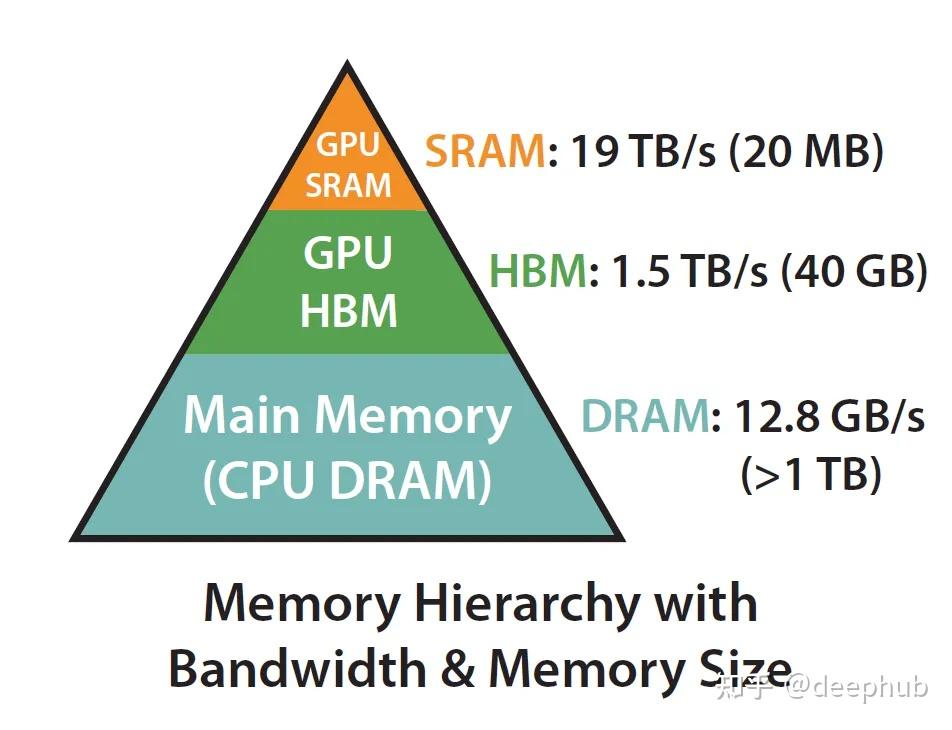
- 静态随机存取存储器(Static Random-Access Memory,SRAM)
- SRAM以其高速访问特性被广泛应用于缓存等场景
- 动态随机存取存储器(Dynamic Random Access Memory,DRAM)
- DRAM则因其较高的存储密度和成本效益被广泛用作主内存。
- 同步动态随机存取内存(synchronous dynamic random-access memory,SDRAM)
- 同步动态随机存取存储器(SDRAM):随着处理器速度的提升,为了减少内存与CPU之间的速度差异,SDRAM被引入,它允许在单个时钟周期内完成数据的读写。
- 双倍速率 SDRAM(Double Data Rate SDRAM, DDR SDRAM)
- DDR SDRAM通过在时钟的上升沿和下降沿都能进行数据传输,实现了数据传输速率的翻倍。
HBM高带宽存储器(High Bandwidth Memory,HBM)
HBM是一种创新的3D堆叠DRAM技术,由AMD和SK海力士联合开发。它通过将多层DRAM芯片垂直堆叠,并使用高带宽的串行接口与GPU或CPU直接相连,从而提供了远超传统DRAM的带宽和容量。
共享KV
多个Head共享使用1组KV,将原来每个Head一个KV,变成1组Head一个KV,来压缩KV的存储。代表方法:GQA,MQA等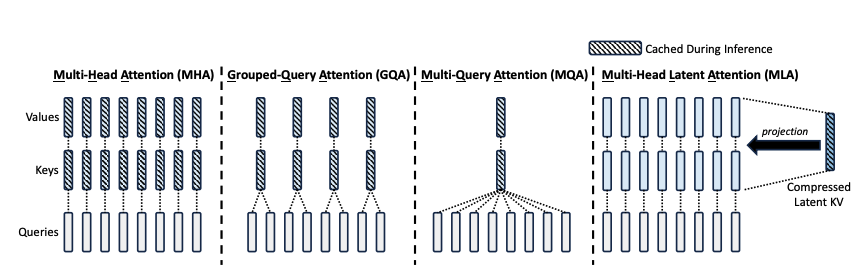
- Multi-Head Attention, 图1, 每一层的所有Head都独立拥有自己的KQV权重矩阵, 计算时各自使用自己的权重计算.
- Multi-Query Attention, 图2, 每一层的所有Head,按照数量分组, 一组的成员, 共享同一个KQV权重矩阵来计算Attention。因此, 分最多组就是MHA(图左), 最少就是MQA(图右).
- Group-Query Attention, 图3, 每一层的所有Head,都共享同一个KQV权重矩阵来计算Attention.
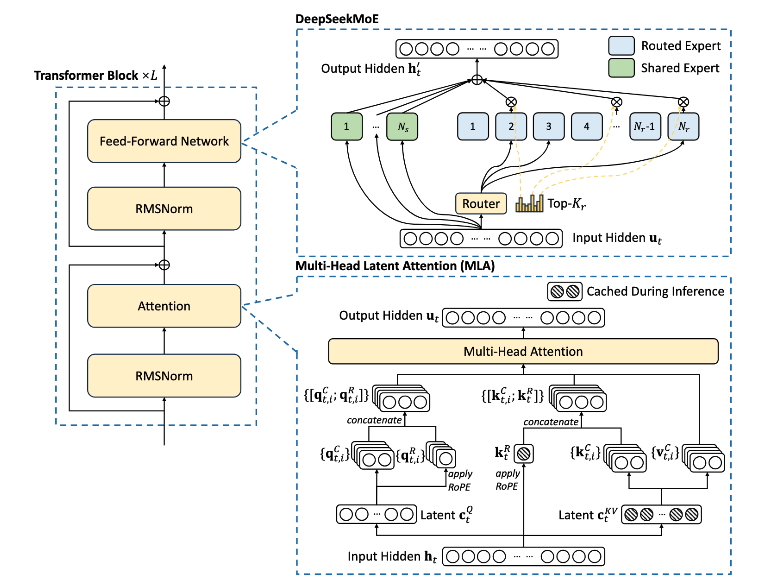
- Multi-Head Latent Attention, 图4, 每个Transformer层,只缓存了权重$c_{t}^{KV}$和$k_{t}^{R}$, 个人认为可以理解为缓存了两个分解的低秩矩阵.
![MLA]()
窗口KV
针对长序列控制一个计算KV的窗口,KV cache只保存窗口内的结果(窗口长度远小于序列长度),超出窗口的KV会被丢弃,通过这种方法能减少KV的存储,当然也会损失一定的长文推理效果。代表方法:Longformer等
量化压缩
基于量化的方法,通过更低的Bit位来保存KV,将单KV结果进一步压缩,代表方法:INT8等
Page Attention
https://zhuanlan.zhihu.com/p/9632325957
参考地址
[1] deepseek-v2
[2] deepseek-v3
[3] deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention)
[4] 知乎: FlashAttention算法详解